Middleware is now a very popular topic in the PHP community, here are some of my thougts on the subject. First, let’s take a quick look at what middleware is ( if you already know about middleware you can skip this part):
Short intro
The idea behind it is “wrapping” your application logic with additional request processing logic, and then chaining as much of those wrappers as you like. So when your server receives a request, it would be first processed by your middlewares, and then after you generate a response it will also be processed by the same set:
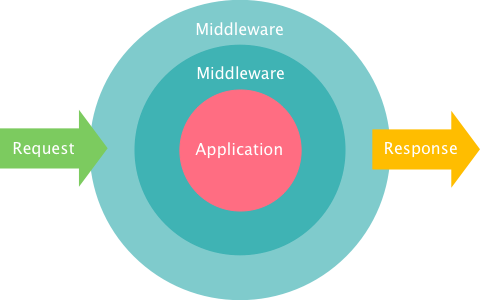
Middleware
It may sound complicated, but in fact it’s very simple if you look at some examples of what could be a middleware:
- Firewall – check if requests are a allowed from a particular IP
- JSON Formatter – Parse JSON post data into parameters for your controller. Then turn your response into JSON before sending ti back
- Authentication – Redirect users who are not logged in to a login page
The coolest part of this is chaining. Since middlewares don’t know about each other it’s simple to find the ones you need and chain them together. And the best part is that after we get PSR-7 we can get sets of middleware that are decoupled from the frameworks and easily interpolable.
This is it for the quick intro, now here are my thoughts:
Replacing controllers
In the picture above notice the application kernel in the middle? My initial thought was: why not consider our application as middleware too ?. Indeed, controllers in our frameworks already read requests and return responses, so pretty much they are also middleware, just without the chaining. The other thing that differs controllers from middleware is tight coupling to the framework, apart from that they are the same. And here it dawned on me:
The application kernel in the above chart shouldn’t be our Controller, since when you follow some proper design rules it’s your models that contain application logic, not the controller. Which means next gen frameworks should dump the Controller concept entirely, and split everything to middleware layers
Problems
There are some problems with middleware though, the biggest on coming from framework independence. The amount of things you can do without utilizing the framework is actualy very small. Interpolable middleware would have no way to access your database, templating, etc. The only way to expose those things in an interpolable way would be for middleware to provide you with a set of required interfaces that you would hvae to satisfy. That’s cool, but it might be far too hard for Junior devs, and eventually not catch on.
Were we using middleware all this time?
All frameworks allow you to specify in your controllers some code that would be executed before and after the action execution, likw this:
class Controller
{
function before()
{
//preprocess, check authorization, do redirects
}
function actionIndex()
{
//actual action
}
function after()
{
//postprocess, handle formatting, etc
}
}
Well in that case your before()/after() has always been your middleware code. And if you wrote your controllers following the thin controller, fat model rule your actions are pretty much middlewares too, since all they do is format data receive from your model layer.
Let’s try inverting
Another issue middleware has that old-style controllers don’t is heavy reliance on configuration. There must be some config file present that will tell which middlewares to chain for a particular route. And what I learned over the years that it’s much better to write code instead of config. You can debug code, it’s harder to debug a misconfigured system. So here I thought, that if controllers and middleware are so simple, perhaps it’s posiible to reverse the idea and write controllers in a middleware fashion, consider this:
class Controller
{
function actionIndex()
{
//assume that each middleware modifies
//the request/response given
if(!$this->auth->isLoggedIn($this-request));
return $this->redirect($this->request);
$this->json->processRequest($this-request);
$response = /* call model layer and build a response */;
$this->json->processResponse($this-response);
return $response;
}
}
I think the above is more readable, debuggable and understandable then chaining middleware in a configuration file. So maybe we don’t really need middleware, just better controller code? Maybe the whole point of middleware is to prevent programmers writing spaghetti code in their controllers ?
Is a HTTP Request enough?
The PSR-7 has one of it’s goals to enable interpolable middleware, but it bases its standard on an HTTP Request. The question is whether data in such a representation is enough to writ middlewares, what if you want to pass some additional request parameters around? In the JSON encode/decode example I mentioned earlier it doesn’t really sound like a very good idea to create a new request converting JSON data into POST form encoded data for the next middleware. This decoding/encoding part is an overhead, that I wish we could avoid. Wouldn’t it be better if it could just decode data and pass it like that?
What I’m thinking is perhaps a better idea would be to have a Request class that is more like a parameter bag, and has nothing to do with HTTP. This way it could be used for even CLI apps. The problem with it is how would it represent things like URLs and headers? I don’t know, but there must be a way.

Recent Comments